Przycinanie drzewa¶
Jak wiemy uczenie algorytmu klasyfikacji polega na dopasowaniu algorytmu do zbioru uczącego. W wielu wypadkach dopasowanie to może okazać się nadmierne co skutkuje przeuczeniem klasyfikatora, a zatem spadkiem zdolności uogólniających. Oznacza to, że klasyfikator mimo iż osiąga bardzo wysoką sprawność na elementach zbioru uczącego nie sprawdza się w dostatecznym stopniu na próbkach których nie obserwował w procesie uczenia.
Przycinanie drzewa (ang. pruning) polega na zastąpieniu pewnych jego węzłów liśćmi, co powoduje uproszczenie drzewa. Ideą tego procesu jest właśnie uproszczenie struktury drzewa bez straty (z akceptowalną stratą) zdolności uogólniających. Przycinanie drzewa można traktować jako element walidacji klasyfikatora i powinno odbywać w oparciu o niezależny od zbioru uczącego zbiór próbek. Ogólny schemat przycinania drzewa ilustruje algorytm 4.
Algorytm 4
Algorytm przycinania drzewa klasyfikacyjnego
Dane: drzewo klasyfikacyjne \(T\), zbiór do przycinania \(X_{prune}\)
Wyniki: Drzewo klasyfikacyjne \(T\) po przycięciu
funkcja przytnij-drzewo \((T,X_{prune})\)
- Dla każdego węzła \(node\) drzewa \(T\):
- Jeżeli sprawność klasyfikacji drzewa \(T\) nie ulegnie zmniejszeniu na zbiorze \(X_{prune}\): zamień węzeł \(node\) na liść \(leaf\) i przypisz mu etykietę klasy najliczniej reprezentowanej wśród elementów zbioru \(X_{prune}\) osiągalnych przez węzeł \(node\)
Można również rozpatrywać przycinanie w bardziej zaawansowanej wersji a mianowicie poprzez zastępowanie węzła przez jeden z jego węzłów potomnych zamiast zastępowania liściem.
Przykład 8
Uzyskane w poprzednim przykładzie drzewo ma dosyć złożoną strukturę, dla zaklasyfikowania elementu testowego potrzeba wykonać nawet 5 testów. Uprościmy jego strukturę determinując maksymalną głębokość drzewa.
from sklearn.datasets import load_iris
from sklearn import tree
#wczytanie zbioru danych
iris = load_iris()
#drzewo klasyfikacyjne z domyślnymi wartościami parametrów
clf = tree.DecisionTreeClassifier()
#dostępne parametry budowy drzewa klasyfikacyjnego
print 'Wartości parametrów drzewa:'
print clf
clf = tree.DecisionTreeClassifier(max_depth=3)
#uczenie drzewa klasyfikacyjnego
clf = clf.fit(iris.data, iris.target)
#testowanie - klasyfikacja elementów zbioru uczącego
y=clf.predict(iris.data)
print 'Uzyskane w toku testowania etykiety:'
print y
#obliczamy liczbę poprawnych zaklasyfikowań i procentową sprawność na zbiorze uczącym
print 'Uzyskana sprawność na zbiorze uczącym:'
popr_zaklas=(iris.target==y).sum()
print 'Poprawnych zaklasyfikowań:'
print popr_zaklas
CR=float(popr_zaklas)/len(y)
print CR
#wygenerowanie pliku pdf repreentującego drzewo
#wymaga pakietu pydot oraz oprogramowania Graphviz
from sklearn.externals.six import StringIO
import pydot
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data)
graph = pydot.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("drzewo_iris.pdf")
Uzyskane drzewo klasyfikacyjne w tym przypadku ilustruje rysunek 3
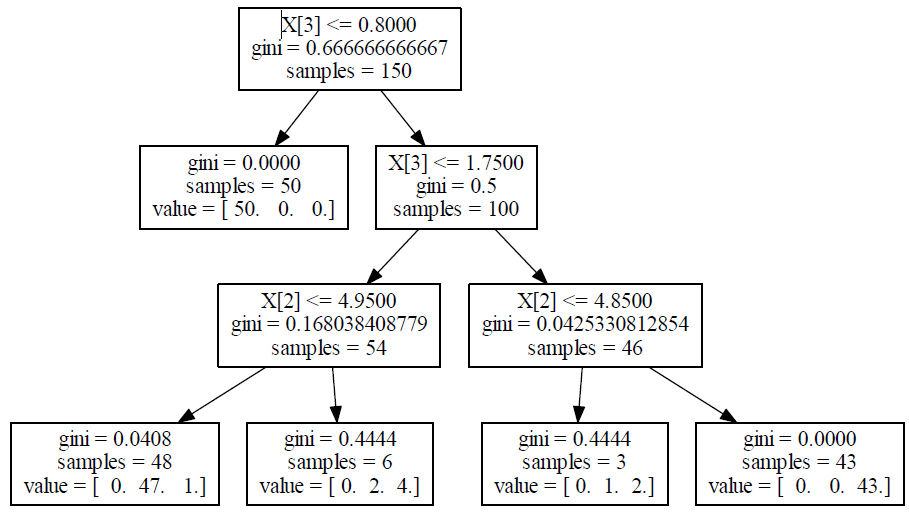
Rysunek 3: Uproszczone drzewo klasyfikacyjne dla zbioru Iris. Źródło: opracowanie własne
Zauważmy, że znacznie uproszczone drzewko klasyfikacyjne uzyskane w powyższym przykładzie ma sprawność przekraczającą \(97%\) (146 z 150 próbek uczących klasyfikuje poprawnie). Pamiętajmy, że testowania klasyfikatora powinno się dokonywać na niezależnym od uczącego zbiorze testowym. Nadmierne dopasowanie drzewa do danych uczących może powodować przeuczenie i spadek zdolności uogólniających. Ocena zdolności uogólniania na próbkach nie biorących udziału w procesie uczenia będzie tematem zadań do samodzielnego wykonania.